
What is a roguelike? First of all, it is my favorite genre of game! Second of all, this is a question that has puzzled enjoyers of the genre for years, as the term "Roguelike" gets applied to everything from the original Rogue to Fortnite.
Developers and players at the International Roguelike Development Conference of 2008 argued for many hours about what defines a Roguelike, eventually deciding on 13 key factors, known as the Berlin Interpretation:
Naturally, much has changed since 2008, and these rules are now seen as guidelines rather than the law. Games that violate much of this definition are still seen as roguelikes by most in the modern day:
All of these roguelites are worth trying, but we'll be focusing on traditional roguelikes; which I personally define as games that meet at least 11 of the aforementioned rules.
Not everyone is going to enjoy a roguelike. These games tend to be very hard to learn and the limited graphics can make it difficult to approach. There's a reason why even the best of this genre tends to be niche! With that being said, I hope I can make my case.
For those willing to brave the procedurally generated depths of a good roguelike, these games have an endless amount to offer.
Because the worlds are randomly generated, each dungeon is different from the last: even in a more bare-bones roguelike, such
as Rusty Roguelike, there are over 1.965377e+13 possible dungeons! This doesn't include features such
as doors and traps either.
The variety extends to loot too; each attempt has the promise of
finding a Blessed +5 Greatsword that can push you farther than any of your previous attempts,
or something that doesn't just rely on raw stats, such as
an Enchanted Hood of Thorns that not only damages your attackers, but heals you every time they get hurt by the thorns!
Another two things that await intreped adventurers would be both enemy variety and, more importantly, mechanical discovery: think
back to the Enchanted Hood of Thorns; it damages enemies that attack you and heals you for the damage that it inflicts. What's
stopping you from focusing your character on healing and then charging in wearing your enchanted hood? If you've played your cards
right, you won't even have to do the attacking! Your adversaries will try in vain to kill you in melee, only instead getting
caught in the magical thorns and healing you for any of the damage they were lucky enough to inflict. A more straighforward
example would be the Cockatrice from NetHack: any flesh touched by this bird will turn to stone. So if you kill the bird
at range, and then wear gloves when you grab it, you can smack monsters with its corpse to instantly turn them to stone!

In short, there are many ways to solve problems and create a character that is both powerful and fun! This is due to the complexity of roguelikes, not in spite of it. Even after hundreds of hours in one of my favorite roguelikes, Caves of Qud, I'm still finding new enemies and items!
Many who are passionate about the genre go on to develope their own roguelikes, it's somewhat seen as a rite of passage in the
community. But don't let the 1990s graphics fool you, this is no easy task! That being said, easy things are rarely fun. So what
would you need to do to make a roguelike?
The two main things you need to consider are systems and random generation. Everything boils down to those and how they interact
with each other. World generation is random generation, but how things happen in the world is governed by systems. I consider
these to be a joy to make! For example, generating a dungeon could be as simple as starting with a grid full of walls, and then
carving X number of rooms by subtracting from the walls each with ≥1 exits, like so:
You can expand from this in innumerable different ways, for example, by adding circular rooms to the mix:
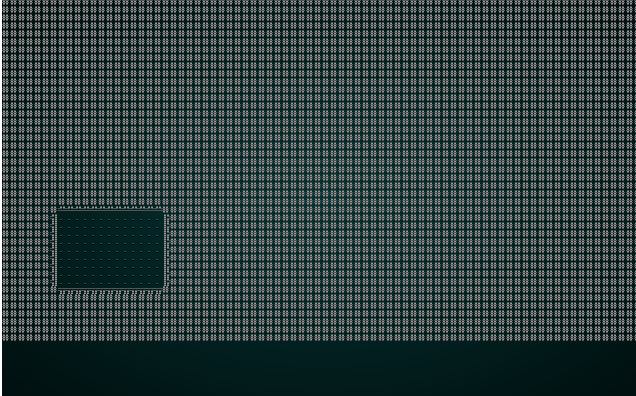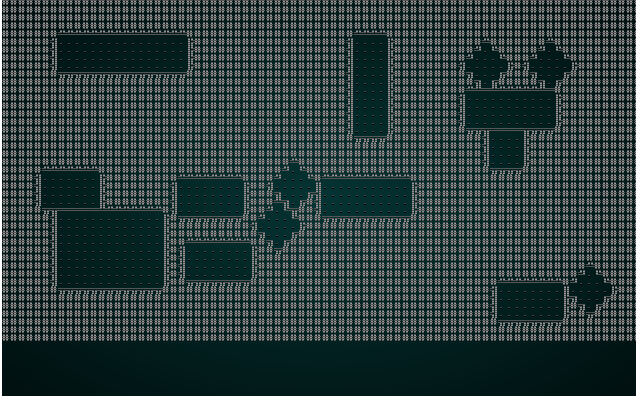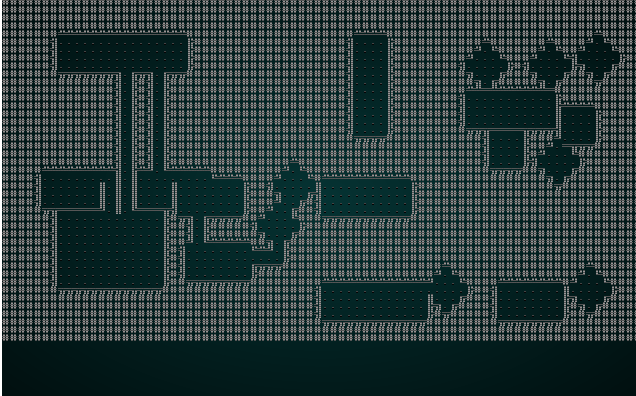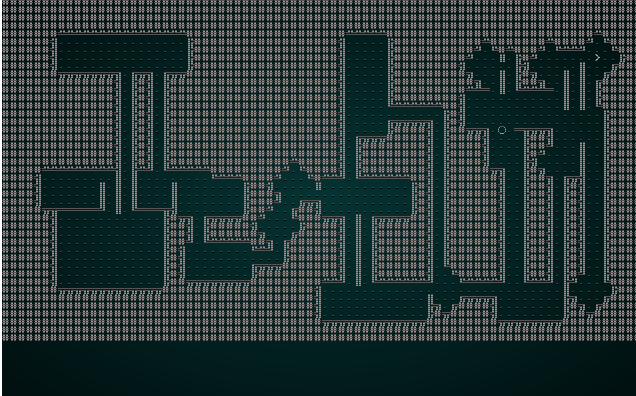
In some roguelikes like ADOM, Dwarf Fortress, or Caves of Qud, there are entire continents to explore; with each section being generated as an explorable chunk. This is where you have the most freedom in design: you can have biomes that alter each chunk by adding different biome-specific tiles and entities, then overlap this with randomly generated structures and natural features. If this sounds familiar, that's because these design choices first made by roguelike developers later influenced Minecraft; Notch is a Dwarf Fortress fan!

Systems are the other side of the roguelike coin, and are a bit tougher to implement (and just as hard to explain!). You have
the basic systems; movement, hit detection, maybe hunger. But things get tricky when you have to calculate skin contact,
magical enchantments, antimagic that could counter said enchantments, and how rusty your mace is whenever you try to beat a monster
to death. There are solutions to this, some
more complicated than others, and all with their own learning curves, pros, and cons.
The good news for developers is, it's your game and you decide the complexity. And with roguelikes especially, you can get started
very quickly and take things bit by bit. Even the most complex roguelike, and in my opinion the most complex game of all time,
Dwarf Fortress, started as one grid with nothing but rock and dwarves.
This is Hebert Wolverson's aforementioned Rusty Roguelike from his Make a Roguelike in Rust series. You can play it right here on my site! Use the numpad to move, I for inventory, G to pick things up, and move into enemies/NPCs to attack/interact with them.
If you want to play a more fleshed-out roguelike, try Dungeon Crawl Stone
Soup. It has over 300 different enemy types and 26 playable classes! The game hase quite the learning curve though,
so I recommend the wiki